In the museums and archives world, we spend an extraordinary amount of time debating what information needs to be embedded in an object or image number. We get paid not-so-big bucks for this. Historically, a lot of unnecessary information led to long digital files names, or a numbering scheme that didn’t withstand the test of time.
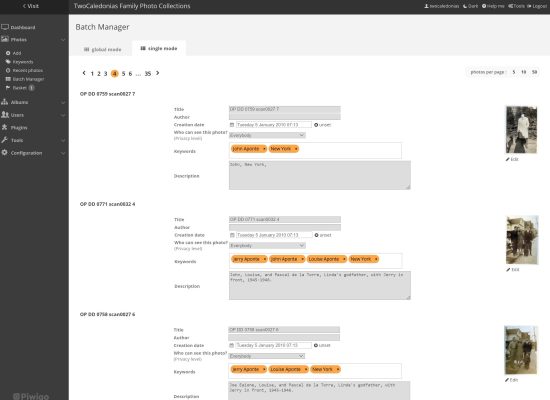
Since my overarching goals were speed and online access to the family collections, I decided that I could save myself some cataloging time by embedding the original format and location of the photo or document in the file name. But every scan, regardless of format, would get a unique four-digit number. I didn’t anticipate that I’d exceed number 9999. I should have gone with five digits and will have to figure that out. It’s already too complicated to go back an add an additional leading zero to over 3500 scans.
The key to file names is below.
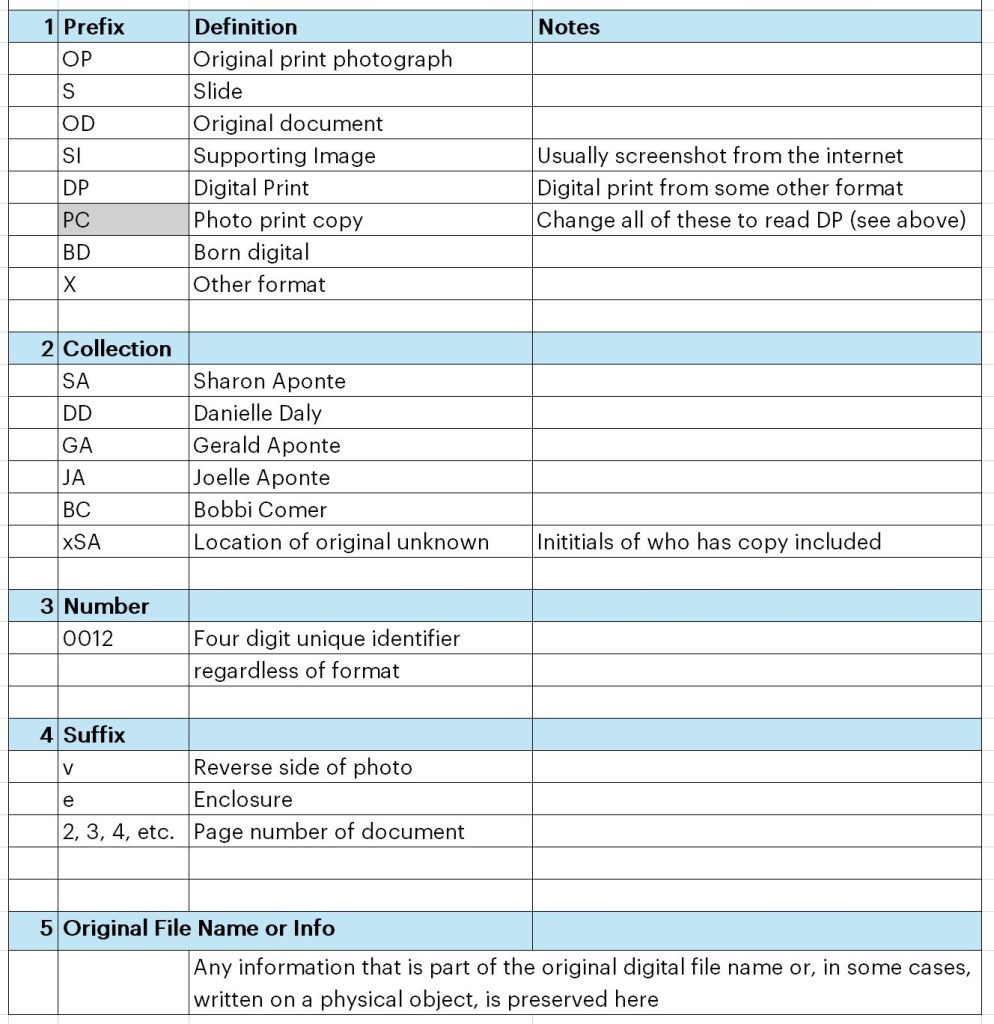
Once a photo is scanned as a TIFF, I used freeware called Advanced Image Renamer to rename the scans according to the schema below. Each image number contains three main and two secondary components. Each is separated by an underscore and is written on the back of the physical photo/document/etc. I also track numbers and the precise location (not only the custodian, but the box, envelope, album, etc.) of the original in an Excel spreadsheet.
Overall, this seems to be working for me. For now.